CuatroLLM niche translations with adaptive in-context learning: exploring English-Filipino
CuatroLLM is a 1.3B parameter four-language machine translator pre-trained on a 300B-token dataset, TransWeb-Edu, which the authors posted on arXiV last October 2024.
Summary
This mini-project focused on CuatroLLM, a 1.3B parameter model pre-trained on four languages: English, French, Spanish, and German. We replicated its baseline results on complex reasoning tasks. Fine-tuning CuatroLLM with a scientific corpus marginally worsens performance in complex reasoning. However, in zero-shot and one-shot scenarios, we demonstrate improvements in fine-tuned CuatroLLM’s English-French translation for the scientific domain. Lastly, we explored CuatroLLM for English-Filipino translation with a small compiled dataset. Including Filipino as part of pre-training could improve this performance, but it would require a larger translation dataset.
This project was done in coordination with Drandreb Earl Juanico and Alister Marc Domilies. Note: This is work done in coordination with the AI351 course of the MEngAI program of the University of the Philippines Diliman.
Introduction
CuatroLLM is a 1.3B parameter large language model (LLM) capable of translating across four languages: English, French, German, and Spanish. It sought improvement in the poor performance of LLM in languages other than English. The problem of machine translation (MT) was the primary subject of original encoder-decoder transformers developed by Vaswani et al, aiming to use what was then a novel architecture for translating English to German and vice versa. Since then, the transformer architecture has seen an explosion in applications that gave rise to LLMs such as GPT, BERT, and their descendants.
Adaptive-MT was another previous approach that aimed to address the quality of LLM machine translators by integrating human feedback, such as corrections to and rating of LLM-generated translations over time, in a reinforcement learning framework. Like CuatroLLM, the study aimed to improve LLM translator performance in low-resource languages. The authors of Adaptive-MT introduced a seamless supervised fine-tuning training (SFFT) protocol and a corresponding evaluation tool for one-shot and few-shot learning from translation examples of a pre-trained LLM, such as Mistral-7B.
The adaptive MT SFFT approach involves presenting a mixture of zero-shot and one-shot examples to the LLM to learn the specific translation patterns in a specific domain. We applied this fine-tuning approach to enhance the performance of CuatroLLM in the niche scientific literature. The implementation is via the supervised fine-tuning trainer SFTTrainer API from Huggingface, which is a crucial step in reinforced learning via human feedback or RLHF, which is the core of Adaptive-MT’s strategy of improving the quality of LLM machine translation.
The present mini-project has three objectives. First, as reported by its authors, the project replicated CuatroLLM’s performance on complex reasoning benchmarks and core machine-translation (MT) metrics. We obtained results of CuatroBen metrics for all four languages it had pre-training: English, French, German, and Spanish. Then, we evaluated CuatroLLM’s MT performance for English-French translations in the scientific literature for which evaluation datasets were available from Moslem et al.
This project also pursued the fine-tuning of CuatroLLM using the adaptive MT approach for English-Filipino translation. However, we should note that CuatroLLM was not pre-trained in Filipino. The composition of Spanish and English words in the modern Filipino vocabulary could aid in-context learning of CuatroLLM on the English-Filipino datasets we compiled.
Methods
The baseline model is the pre-trained CuatroLLM, generated by training from scratch a Mistral-7B-Instruct-v0.1 model on a quadrilingual dataset, \emph{TransWeb-Edu}, which the authors compiled. We then compared the baseline performance with two fine-tuned versions: (1) CuatroLLM generated by the authors by continuous training with additional RedPajama-v2 dataset and cooldown datasets that included Python-Edu, WebInstruct, and WebInstruct-French; and (2) CuatroLLM fine-tuned via supervised fine-tuning training (SFTT) through the in-context learning with human feedback developed by Moslem et al. for adaptive MT.
The SFTT employed a parameter-efficient fine-tuning (PEFT) with a low-rank adaptive (LoRA) alpha of 16 and dropout of 0.1. This PEFT model generated a version of the pre-trained CuatroLLM that is lighter to fine-tune with a few GPUs. We froze the tokenizer during SFFT training, which is contrary to the fine-tuning method applied by Wang et al. to obtain their fine-tuned \emph{CuatroLLM-cool}~. We then evaluated the complex reasoning task performance of the baseline and fine-tuned CuatroLLM. We replicated these metrics for baseline CuatroLLM on the four languages that CuatroLLM had pre-training.
Fine-tuning datasets from Moslem et al. were available for French and Spanish. We fine-tuned CuatroLLM on these languages using the adaptive MT approach and compared their CuatroBen metrics to the baseline model. Subsequently, we assessed the CuatroLLM MT performance for English-French translations using BLEU, chrF++, and TER. We examined both zero- and one-shot translations and compared them to their corresponding results reported in the paper.
Finally, we fine-tuned a baseline CuatroLLM for English-Filipino translations even if CuatroLLM did not have pre-training in Filipino. We compared CuatroLLM’s performance for this type of translation with NLLB, which is a suitable benchmark.
Results
| Tasks | French Ppr | French Rpl | German Ppr | German Rpl | Spanish Ppr | Spanish Rpl | English Ppr | English Rpl |
|---|---|---|---|---|---|---|---|---|
| ARC-C | 33.53 | 33.45 | 31.39 | 32.42 | 32.99 | 32.91 | 38.23 | 37.88 |
| Hellaswag | 38.00 | 37.79 | 35.70 | 35.54 | 38.66 | 38.81 | 41.42 | 41.30 |
| PAWS-X | 52.10 | 53.90 | 51.35 | 52.05 | 50.00 | 52.55 | 49.75 | 52.95 |
| TruthfulQA | 26.43 | 26.30 | 26.90 | 28.81 | 27.88 | 28.64 | 24.11 | 23.99 |
| XNLI | 42.61 | 43.01 | 42.57 | 44.21 | 42.97 | 43.29 | 46.91 | 45.98 |
| mean | 38.53 | 38.89 | 37.58 | 38.61 | 38.50 | 39.24 | 40.08 | 40.42 |
| p-value | 0.397 | 0.048 | 0.192 | 0.670 |
Table 1: CuatroBen metrics on complex reasoning tasks of baseline CuatroLLM; “Ppr” stands for results in the paper [6 ], while “Rpl” indicates our replicated results. The two-tail 𝑝-values in the last row indicate that, except for German, the differences between the paper’s results and our replications are not significant at the 𝛼 = 0.05 level.
| MT Metrics | Paper baseline (pretrained) | Replicated baseline (0-shot) | Replicated baseline (1-shot) | Paper fine-tuned (cool) | Replicated fine-tuned (0-shot) | Replicated fine-tuned (1-shot) |
|---|---|---|---|---|---|---|
| BLEU | 24.73 | 18.95 | 34.14 | 30.88 | 33.51 | 43.39 |
| chrF++ | NA | 43.95 | 56.25 | NA | 56.49 | 62.85 |
| TER | NA | 88.44 | 65.69 | NA | 63.37 | 52.84 |
Table 2: English-French translation performance of baseline and fine-tuned CuatroLLM in zero-shot and one-shot settings. The “NA” means that the CuatroLLM authors did not evaluate such metrics.
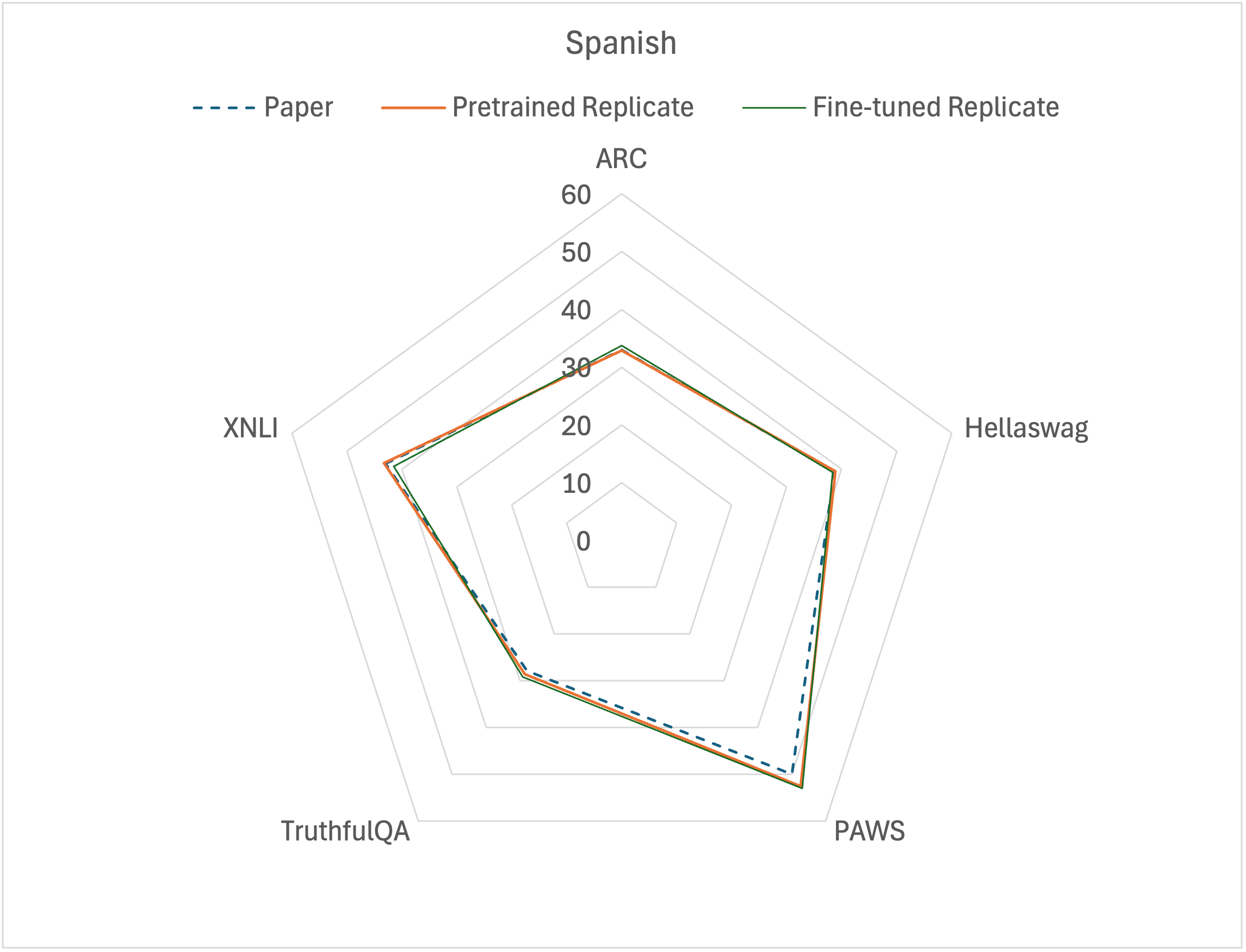
The impact of fine-tuning in CuatroLLM’s reasoning capabilities assessed by various benchmark tasks. Refer to Table 4. 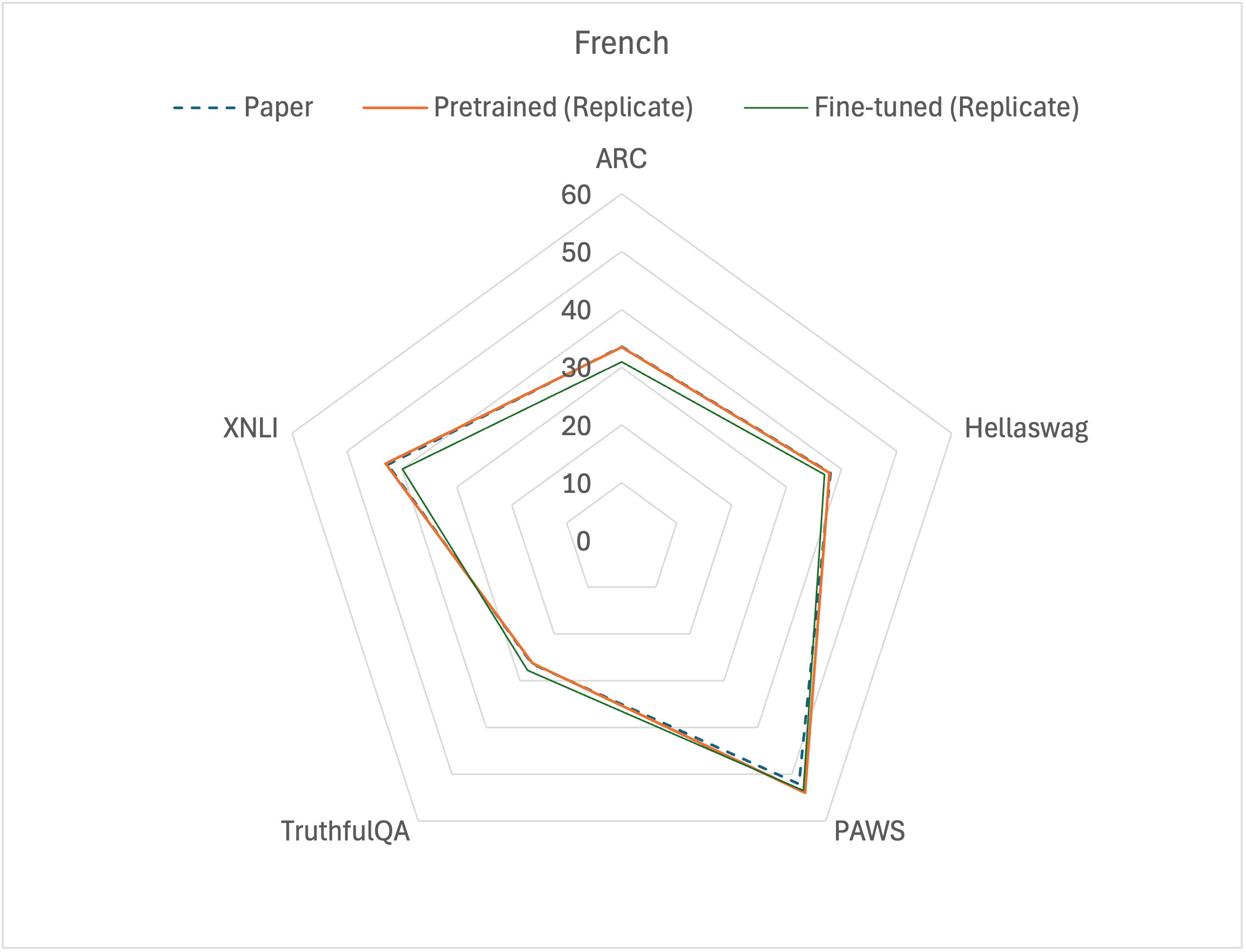
| MT Metrics | CuatroLLM (0-shot) | CuatroLLM (1-shot) | NLLB (0-shot) | NLLB (1-shot) |
|---|---|---|---|---|
| BLEU | 0.08 | 0.14 | 40.14 | 7.56 |
| chrF++ | 4.89 | 6.25 | 61.79 | 30.25 |
| TER | 122.35 | 116.4 | 50.53 | 214.24 |
Table 3: Comparison of CuatroLLM and NLLB MT performance on English-Filipino translations.
We replicated the complex reasoning benchmarks presented by the authors in the paper~\cite{cuatrollm} on all metrics included in CuatroBen. With a two-tailed $t$-test, we tested the statistical significance of the differences between the paper’s results and our replication. Our evaluation results in Table~\ref{tab:cuatroben_all} reveal that the differences are mostly insignificant at the $0.05$ level. Thus, we achieved our first objective of replicating the paper’s results from evaluating CuatroLLM on complex reasoning tasks in four languages.
The authors’ results~\cite{cuatrollm} for machine translation lie in between the baseline CuatroLLM’s zero-shot and one-shot performance based on BLEU for English-French translations~(Table~\ref{tab:bleu_enfr}). Hence, CuatroLLM performs poorly in zero-shot translations of niche scientific literature. However, one-shot translation performance improved, showing CuatroLLM’s latent capability to capture style and jargon in a specific domain with a single example. CuatroLLM generated more accurate translations by adhering better to pre-approved terminology and preferred style requirements in the scientific literature if given one example first before it provides the requested translation.
The authors of the CuatroLLM paper did not evaluate chrF++ and TER metrics. However, according to the evaluation protocol established by Moslem et al. for Adaptive MT, we posted these on the table for completeness.
We also compare the results from the fine-tuned CuatroLLM, which the authors obtained by continuous training on an expanded one that included the dataset RedPajama-v2 and some cooldown datasets such as Python-Edu, WebInstruct, and WebInstruct-French, with those from a fine-tuned CuatroLLM obtained through adaptive MT fine-tuning~\cite{adaptivemt}. We see that our fine-tuned CuatroLLM offers more accurate EN-FR translations in niche scientific literature, even in zero-shot performance, than the fine-tuned model from the paper (see Table~\ref{tab:bleu_enfr}). This result implies that the pre-training dataset Trans-Web-Edu is sufficient to capture the EN-FR styles that adaptive MT could improve in real time with a few examples. Not only is this advantageous in saving memory space for additional datasets, but it also keeps CuatroLLM small by not needing to add more tokens. The baseline CuatroLLM required 515B tokens, whereas the fine-tuned version reported in the paper required 625B tokens.
The fine-tuning of LLMs to improve on specific downstream tasks usually leads to the catastrophic forgetting of pre-trained capabilities~\cite{catastrophic}. In most tasks for Spanish and French, the fine-tuned CuatroLLM was worse than the pre-trained one (Figure~\ref{fig:cuatroben_spanish_french}). However, on the TruthfulQA task, the fine-tuned CuatroLLM presented the best performance. This positive result confirms the scientific niche of the fine-tuning corpus. The in-context learning method by Moslem et al.~\cite{adaptivemt} enabled the pre-trained CuatroLLM to capture the niche style of translating English to French inherent to the specialized corpus. Moreover, fine-tuning also improved CuatroLLM’s PAWS performance in cross-lingual paraphrasing.
Lastly, we attempted to extend the capabilities of CuatroLLM by fine-tuning it with a small English-Filipino dataset we gathered. However, note that Filipino is not in CuatroLLM’s pre-training. The modern Filipino vocabulary consisting of English and Spanish words could facilitate fine-tuning. However, our results revealed otherwise (see Table~\ref{tab:bleu_enfil}), likely due to the small size of our fine-tuning dataset. Also, our assumption that the presence of English and Spanish words in Filipino may not hold for a small dataset.
Conclusion
The focus of the mini-project was to replicate the performance of \emph{CuatroLLM}. For complex reasoning tasks, we successfully obtained metrics close to the benchmark values as reported by Wang et al.~\cite{cuatrollm}. With the available test dataset for English-French translation, we found that the BLEU value reported by Wang et al. is well within the zero-shot and one-shot performance we obtained for baseline CuatroLLM on niche translations with another test dataset from Moslem et al.~\cite{adaptivemt}. The fine-tuning method proposed by Moslem et al.~\cite{adaptivemt} worked effectively in improving CuatroLLM’s zero-shot and one-shot niche translations without adding datasets and extending the number of tokens. Our attempt to fine-tune CuatroLLM with this strategy to perform English-Filipino translations, however, did not succeed which is likely because relying on the presence of English and Spanish words in Filipino to teach translation patterns during fine-tuning may require a larger dataset to work.
Acknowledgements
To Dr. Miguel Remolona, for the semester filled with learning.
References
- Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. 2024. Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv preprint arXiv:2403.14608 (2024).
- Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- Yong Lin, Lu Tan, Hangyu Lin, Zeming Zheng, Renjie Pi, Jipeng Zhang, Shizhe Diao, Haoxiang Wang, Han Zhao, Yuan Yao, et al. 2023. Speciality vs generality: An empirical study on catastrophic forgetting in fine-tuning foundation models. arXiv preprint arXiv:2309.06256 (2023).
- Yasmin Moslem, Rejwanul Haque, John D Kelleher, and Andy Way. 2023. Adaptive machine translation with large language models. arXiv preprint arXiv:2301.13294 (2023).
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need.(Nips), 2017. arXiv preprint arXiv:1706.03762 10 (2017), S0140525X16001837.
- Jiayi Wang, Yao Lu, Maurice Weber, Max Ryabinin, Yihong Chen, Raphael Tang, and Pontus Stenetorp. 2024. Multilingual Pretraining Using a Large Corpus Machine-Translated from a Single Source Language. arXiv preprint arXiv:2410.23956 (2024)
Appendix
| Tasks | French Ppr | French Prt | French FT | Spanish Ppr | Spanish Prt | Spanish FT |
|---|---|---|---|---|---|---|
| ARC-C | 33.53 | 33.45 | 30.88 | 32.99 | 32.91 | 33.76 |
| Hellaswag | 38.00 | 37.79 | 36.83 | 38.66 | 38.81 | 38.31 |
| PAWS-X | 52.10 | 53.90 | 53.50 | 50.00 | 52.55 | 53.05 |
| TruthfulQA | 26.43 | 26.30 | 27.83 | 27.88 | 28.64 | 29.15 |
| XNLI | 42.61 | 43.01 | 39.96 | 42.97 | 43.29 | 41.53 |
| mean | 38.53 | 38.89 | 37.80 | 38.50 | 39.24 | 39.16 |
Table 4: The impact of fine-tuning in CuatroLLM’s reasoning capabilities assessed by various benchmark tasks.